Dirty Data Kills Automation Projects Before They Start. Here’s What to Look for Before You Build.


Agentic AI can act on its own, but title insurance carries real consequences when it gets things wrong. Here is how TrueFocus thinks about where automation belongs and why we keep people at the critical decision points.

Most title executives overestimate what automation costs. Here’s a look at real project numbers, when the math actually works, and why starting with one high-confidence process is almost always the right strategy.

The biggest fear in title operations isn’t cost or timeline. It’s job security. Here’s what automation actually does to your team and why throughput, not headcount reduction, is the real goal.

Most title automation only handles steps inside one system, leaving the manual work in between untouched. Here’s where the real time sinks live.

Most title automation projects fail before they start. Three questions on ROI, technical fit, and strategic control reveal whether yours is ready to build.

We recently joined the NIAS (National Independent Agency Services) Vendor Partner Marketplace as a technology partner. For title companies looking to cut costs, facilitate additional revenues, and enhance services, this curated network simplifies the vetting of automation providers. Read why we are not treating this like a press release, but as a commitment to operational excellence.

A mid-size title company processing 1,000 orders per month can spend over $190,000 in two years on a bot they do not own. TrueFocus walks through the true cost of transactional RPA pricing, when SaaS makes sense, and how to calculate your ownership breakeven point.

A mid-size title company processing 1,000 orders per month can spend over $190,000 in two years on a bot they do not own. TrueFocus walks through the true cost of transactional RPA pricing, when SaaS makes sense, and how to calculate your ownership breakeven point.

Most mortgage and title companies are trapped in a cycle of constant hiring and firing to keep up with market changes. TrueFocus Automation breaks this pattern by integrating advanced RPA and AI into your existing workflows. Our proven solutions have already returned over 1.3 million hours to our clients. By automating manual data entry and order tracking, we help your business achieve up to a 50 percent reduction in processing costs while allowing your core team to focus on high-value tasks.
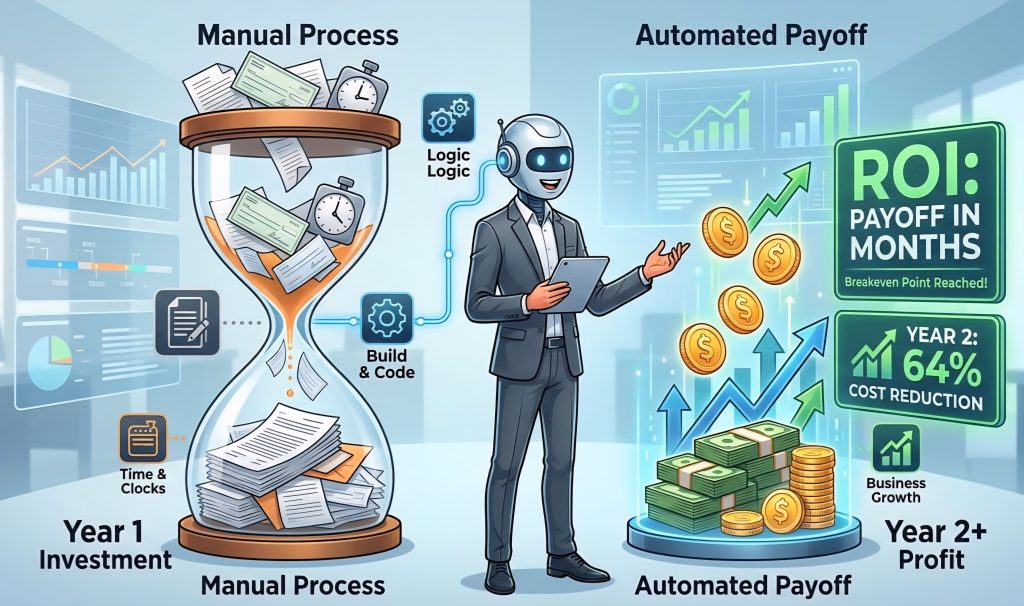
Most automation projects take years and cost hundreds of thousands, but they don’t have to. Title and mortgage companies can start small, automate high-impact processes, and see measurable ROI in just weeks. Learn how to cut manual work, save thousands, and scale automation efficiently.

Learn why title insurance domain expertise is more critical than the technology deployed when automating title processes.

Learn why title insurance domain expertise is more critical than the technology deployed when automating title processes.